Motivation
Authentication confirms that users are who they say they are. Authorization gives those users permissions to access a resource. Ubicloud uses Rodauth for authentication. For authorization, we need to implement a system that gives users the flexibility they need to access various resources across different cloud services on the cloud. Today, there’s a big bifurcation of how authorization is implemented in the cloud. Hyperscalers such as AWS, Azure, and GCP, have powerful authorization models. Other cloud and hosting providers only have authorization at the most basic level (a user has access to a project or not). Ubicloud’s authorization intends to deliver something as powerful as the Identity Access Management (IAM) seen on the hyperscalers. It’s in active development, so expect to see major adjustments.Background
There are two common security models on the cloud today: role-based access control (RBAC) and attribute-based access control (ABAC). In RBAC, an administrator puts users into roles. Then permissions to resources are defined over these roles. For example, an administrator puts the user “Enes Cakir” into “engineering” and “devops” roles. The “devops” role can then access production resources and make deployments. ABAC takes this one step further, where permissions to resources are defined over attributes. In addition to roles, attributes can also include things like a user’s location, client device type, or authentication method. For example, the user “Enes Cakir” can access production resources when he’s in Europe, but not when he’s in the US. This ensures that organizations can define flexible policies to meet their business needs. Tailscale has a great blog post that describes security policies, RBAC, and ABAC in more detail. All three hyperscalers seem to be moving towards the ABAC model. You can read more about AWS, Azure, and GCP’s ABAC designs on their websites. These designs rely on conditional expressions and are more complex than a clean-sheet ABAC design. This is probably because all hyperscalers need to be backwards compatible with their RBAC designs. We’d like to provide something much simpler, both in design and implementation.An ABAC example
In the following, we start with an ABAC example and build on top of it. The following diagram describes a simple scenario, where the users on the left have associated “tags” (classic roles) and the resources on the right also have “tags”.
<subject, action, object>, we introduce the notion of tags. We can associate each subject or object with one or more tags. These four concepts give us an enormous amount of flexibility with our authorization model. In the example above, a user or organization can create fine-grained access policies simply by assigning the right tags to users and resources.
Today, Ubicloud’s tags are user assigned. We don’t have any computed tags over dynamic attributes, such as geolocation. We did this to start simple and grow our authorization model with actual customer needs.
Making users not worry about ABAC
Of course, most users who are new to Ubicloud shouldn’t need to learn about ABAC. Intuitively, after they sign up, they should be able to create, view, and destroy resources on Ubicloud. They should also be able to invite and collaborate with other users on the platform. To enable this, we introduce the notion of “hyper tags.” Each user and resource in the below diagram has a hidden tag, whereby the hidden tag has the same name as its associated user or resource. This way, after a user comes in, they can create new resources and act on the resources they have created without knowing about ABAC.
Avoiding naming collisions in ABAC
One remaining problem with our ABAC example is naming collisions. It’s likely for different organizations and users to create tags with the same name. For example, “prod”, “engineering”, “devops”, “database”, etc. are all common tag names. To avoid naming collisions, we qualify every tag’s name with a namespace. We then use these fully qualified names for authorization. For example, in the example below, Daniel is tagged as belonging to the engineering and devops organizations. So, he can access and deploy code both to dev and prod environments. On the other hand, Enes is only tagged with belonging to the engineering team and can therefore only deploy to the dev environment.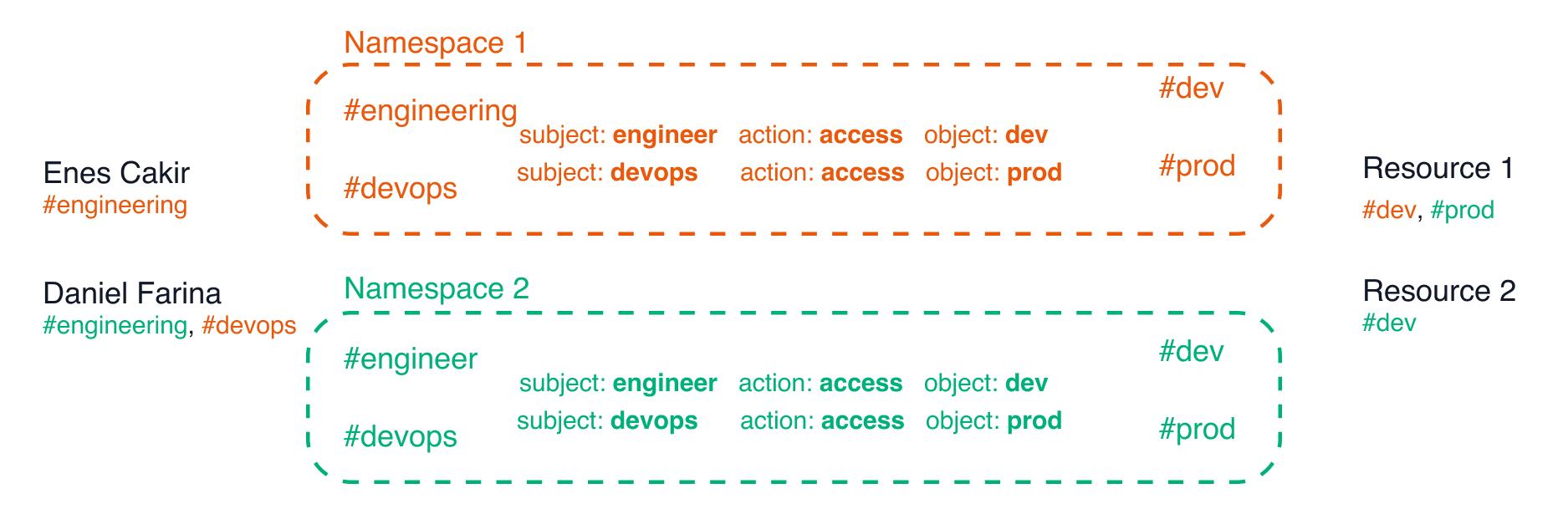
ABAC design
Our ABAC design follows this simple yet powerful example. All we need to do is map the concepts we’ve introduced above into a data model. In our case, it turns out we need five PostgreSQL tables to implement an ABAC authorization model for the cloud.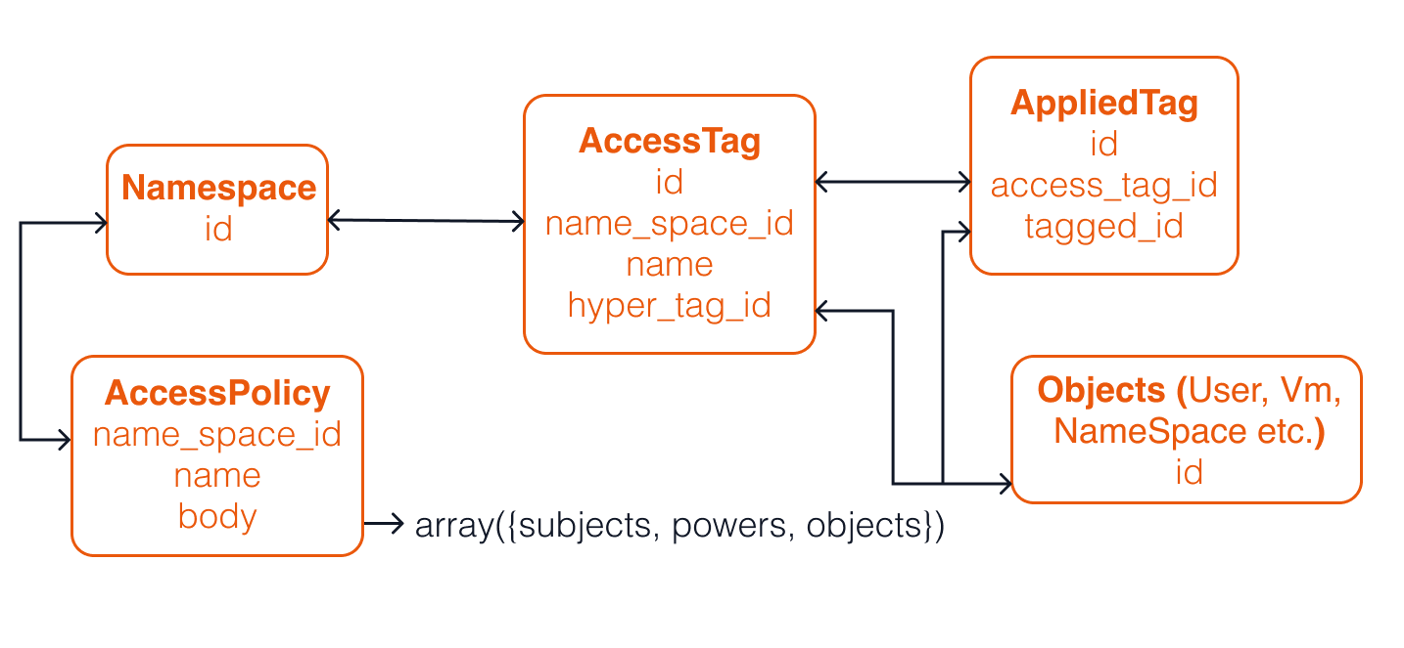
- An access policy table that represents the relationship between
<subject, action, object>. Remember the subject here is the user and the object is the resource - A namespace table to avoid naming collisions
- An access tags table to represent tags (we thought the name tags was just too generic, so picked something more descriptive)
- An items table to represent subjects and objects
- An applied tags table - this is an intermediary/pivot table that we use to establish a many to many relationship between items and tags
ABAC implementation in 130 lines of code
With our ABAC concepts mapped onto five PostgreSQL tables, all we need for authorization is to check if a path exists from a subject (a user identified with one or more tags) to the object (a resource identified with one or more tags). We can do this through the following SQL query.- It’s powerful. We can express all attribute-based access control policies with this one query, for user-defined tags.
- It has an existence proof. When you run the query, if it returns a tuple, the subject can access the object. If it doesn’t, the subject isn’t authorized. Further, you can see all access paths from the subject to the object by looking at the tuples this query returns.
- It’s simple. We get an ABAC implementation in 10 lines of SQL. In fact, the entire file that implements our authorization policy is 130 lines of code.